Het kickstarten van AI in de productie
Toepassingsgebieden, openbaar toegankelijke datasets en succesvolle implementatie

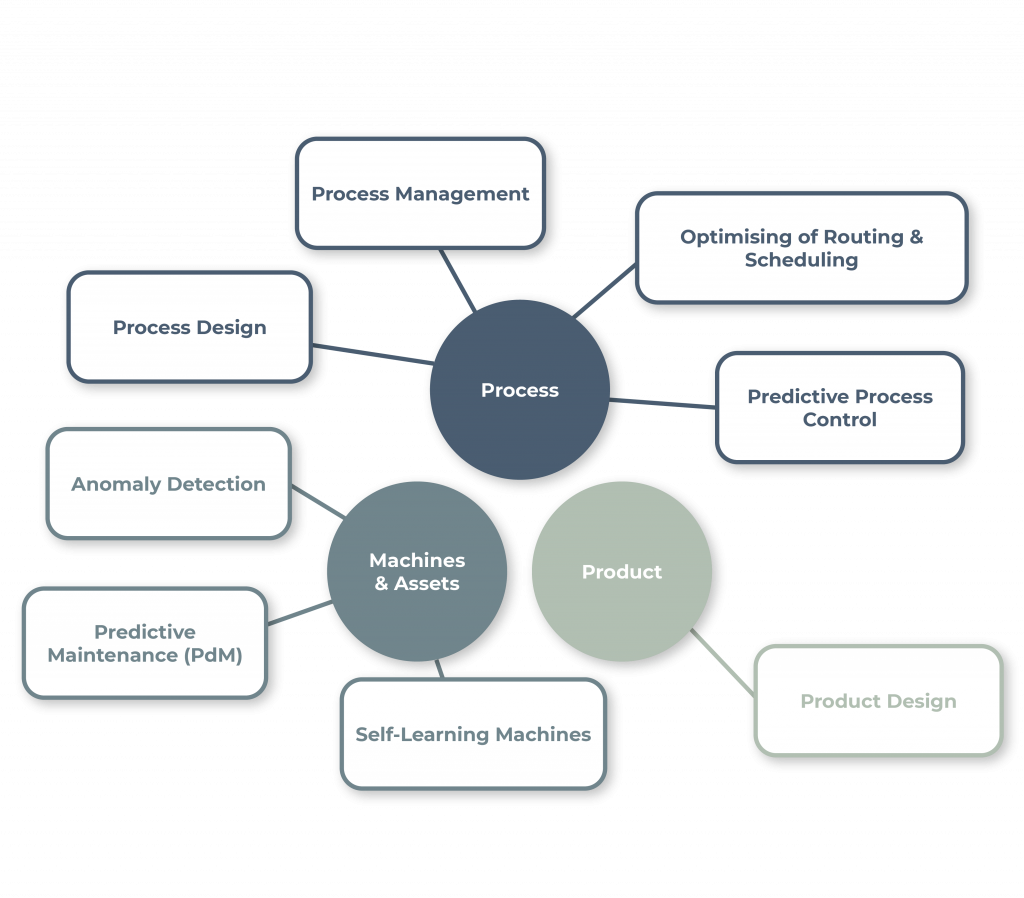
Figuur 1: Overzicht van de toepassingsgebieden: Proces, Machines & Installaties, en Product. Hieronder worden de toepassingsgebieden en toepassingen in de productie omschreven.[3–5, 7–11, 13]
Het vergroten van de rekenkracht en betere databases, met tegelijkertijd dalende kosten voor computer- en opslagcapaciteit, vormen de basis voor het gebruik van Machine Learning (ML) in de productie. Als gevolg hiervan worden ML-methoden in toenemende mate gebruikt in de productie-industrie. ML-methoden kunnen onder andere worden toegepast om kunstmatige intelligentie (ofwel “Artificial
Intelligence“, AI) te trainen, waarvan het merendeel van de bedrijven hoopt dat het de productiviteit zal verhogen. [1] Uitdagingen op het pad naar AI-systemen in de eigen productie zijn onder meer het identificeren van veelbelovende toepassingsgebieden, het herkennen van de bijbehorende learning tasks en het ontdekken van geschikte datasets.
Toepassingsgebieden voor AI en ML in productie
De beslissing om ML in de productie toe te passen, wordt om uiteenlopende redenen en door verschillende verantwoordelijken genomen. In sommige gevallen is het de proceseigenaar die een specifiek probleem wil oplossen, in andere gevallen is het het management dat het gebruik van ML wil testen. Een belangrijk uitgangspunt is daarbij in ieder geval de keuze voor het juiste toepassingsgebied van ML binnen het bedrijf.
Bestaande studies die een overzicht geven van mogelijke toepassingsgebieden, houden vaak slechts rekening met gedeeltelijke aspecten van moderne productiefaciliteiten. Een hoge mate van abstractie of een gebrek aan actualiteit betekent dat deze studies slechts in beperkte mate geschikt zijn om de eigen problemen van het bedrijf te identificeren. [2–13]
Om een basis te bieden voor de selectie van een use case, heeft het Fraunhofer IPT de toepassingsgebieden in figuur 1 geïdentificeerd. Deze zijn gebaseerd op eigen studies en ervaringen uit industrie- en onderzoeksprojecten. De use cases kunnen worden onderverdeeld in drie clusters: Process, Machines & Assets, en Product, ofwel processen, machines en installaties, en het product. Via het overzicht kunnen nieuwe projecten worden geïdentificeerd en zijn startpunten voor ataverzameling in de productie te vinden.
Om projecten te prioriteren, is het noodzakelijk om te beoordelen of de bijbehorende databasis voldoende is. Dit is mogelijk als het projectteam interdisciplinair is en de medewerkers bekwaam zijn op het gebied van data science. Naast theoretische kennis, dienen betrokken medewerkers ervaring te hebben met de toepassing van ML met concrete datasets.
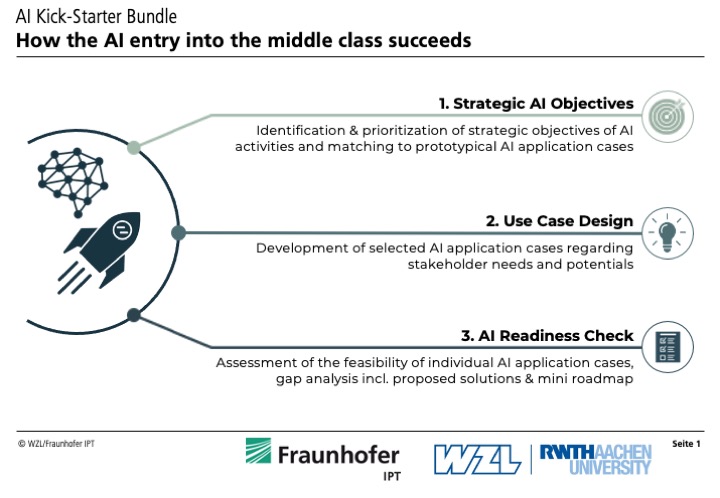
Figuur 2: AI Kick-Starter-pakket van Fraunhofer
Gegevensbasis in de productie
Het gebrek aan ervaring van werknemers in het omgaan met AI en ML leidt ertoe dat een groot aantal ML-projecten faalt, ondanks toenemende datavolumes [14, 15]. Eén van de redenen voor het gebrek aan ervaring, is dat de interne gegevens van de onderneming ongestructureerd zijn, de relevante informatie niet bevatten of niet in toereikende hoeveelheid worden opgeslagen. In deze gevallen is het mogelijk om eerst ervaring op te doen met ML met behulp van vrij beschikbare datasets. Openlijk toegankelijke datasets op het gebied van productie worden echter opgeslagen op verschillende platforms [16].
Om deze redenen heeft het Fraunhofer IPT openbare datasets beschikbaar gemaakt om de eerste ervaringen op te doen gericht op “productie”. Deze beschikbare datasets kunnen worden toegewezen aan de hierboven genoemde toepassingsgebieden. Het volledige overzicht is toegankelijk via de link ipt.fraunhofer.de/ml-and-ai-in-production.
AI en ML succesvol toepassen
Zodra het toepassingsgebied is gedefinieerd en de nodige ervaring is opgedaan, zal een toekomstige uitdaging voor bedrijven zijn om de processen en producten waarin de AI-systemen worden gebruikt, te certificeren. Het beperkte determinisme van ML-modellen zal leiden tot een heroverweging bij de betroffen entiteiten en wordt actief vormgegeven door het Fraunhofer IPT en de Fraunhofer Big Data AI Alliance [17–23].
Samengevat zijn de twee grootste obstakels voor bedrijven op dit moment het identificeren van de meest veelbelovende AI-use cases, en het realistisch beoordelen van de bijbehorende databasis. Zoals beschreven in het artikel, zou de bedrijfsstrategie moeten zijn om intern expertise op te bouwen. Daarnaast is het een goed idee om samen met externe partners de eerste stappen te zetten op weg naar een AI-project. De “AI Kick-Starter”-service, die binnen de Fraunhofer-community is ontwikkeld (zie figuur 2), is een kans voor bedrijven om hun use cases gericht te evalueren en prioriteren [24].