AI in collaboratieve robotica

In het tijdperk van Industrie 4.0 zijn collaboratieve robots een van de belangrijkste pijlers die flexibele automatisering mogelijk maken. Met name dualrobot-systemen worden steeds vaker gezien als een veelbelovende trend van industriële automatisering voor assemblage- en pick-and-place-taken. Dual-robotsystemen bestaan uit twee samenwerkende robotarmen en bieden voordelige eigenschappen. Een hoge redundantie kan bijvoorbeeld de flexibiliteit bij taakmanipulatie verbeteren, terwijl gesynchroniseerde manipulatie de bewerkingstijden kan verkorten.
Om een systeem met twee robots te implementeren, wordt veel aandacht besteed aan taakplanning. De twee armen moeten in tijd en ruimte met elkaar worden gesynchroniseerd om botsingen te voorkomen en om de efficiëntie in termen van bedrijfstijd te verbeteren. Bovendien moeten perifere componenten en werkstukken of werkstukpositioneerders worden overwogen om haalbare banen te definiëren, d.w.z. reeksen van zesdimensionale posities in de cartesiaanse ruimte, voor beide robotarmen. Om economisch voordeel te halen uit dual-robotsystemen, moet de inspanning voor taakplanning ook worden geautomatiseerd om de insteltijd aanzienlijk te verkorten. In navolging van dit idee stelt dit werk een op AI gebaseerde oplossing voor een systeem met twee robots voor dat autonome trajectplanning mogelijk maakt voor een bepaalde pick-and-place-taak door de insteltijd te minimaliseren en botsingen te voorkomen.
Er is gekozen voor een pick-and-place use-case als illustratief voorbeeld om het voorgestelde algoritme te verifiëren. Binnen de use case worden 16 cilindrische pennen gepalletiseerd van een pallet naar een draaitafel. Het systeem bestaat uit twee KUKA KR 10 R1100-robots met elk zes vrijheidsgraden. Beide robots zijn uitgerust met tweevingergrijpers en delen een gemeenschappelijke werkruimte. De systeemconfiguratie wordt weergegeven in afbeelding 1.
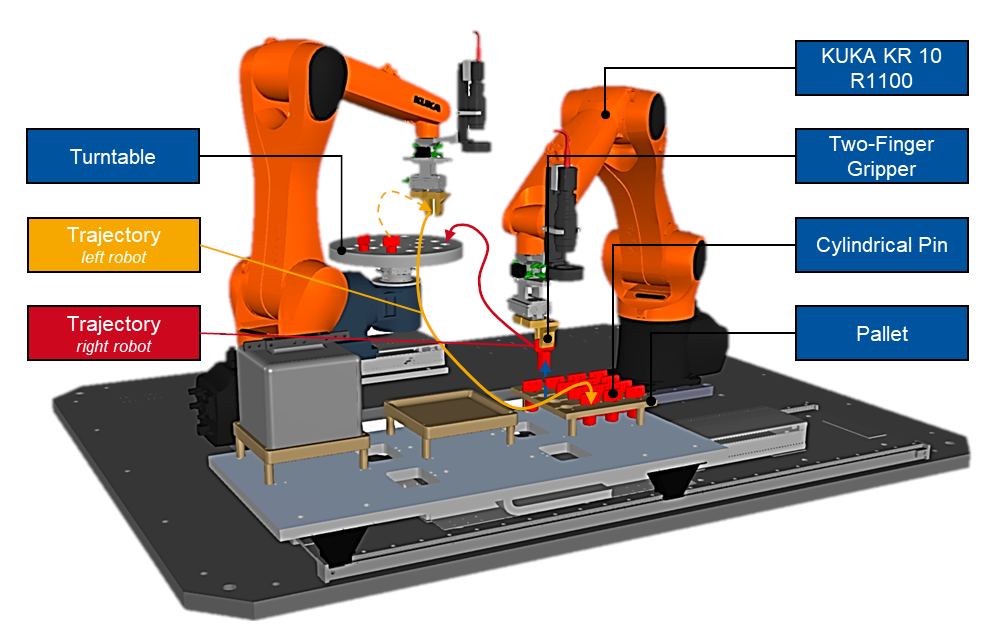
Figuur 1: Componenten van het dual-robot systeem.
Probleemverklaarders
Het probleem van robotbaanplanning is de bepaling van zesdimensionale posesequenties op een gedefinieerde tijdstap die de robot zal naderen met zijn gereedschapsmiddelpunt (TCP) om een gewenste beweging uit te voeren. Enerzijds vertonen robotmanipulatietaken over het algemeen een hiërarchische structuur. Aan de andere kant demonstreert eerder werk de geschiktheid van op AI gebaseerde trajectplanning voor opstellingen met één robot. Onze aanpak maakt gebruik van en combineert deze twee bevindingen voor opstellingen met meerdere robots door een hiërarchische besturingsarchitectuur te ontwerpen die een raamwerk vormt voor systemen met meerdere agenten (zie afbeelding 2 links): een superieure managerlogica houdt toezicht op de uitvoering van de algehele taak en wijst subtaken toe aan verschillende gespecialiseerde agenten. Elke individuele agent is verantwoordelijk voor de trajectplanning van een bepaalde robot op een bepaald moment en is ontworpen als een agent voor diep versterkend leren (DRL).
Aanpak
Het doel is om agenten in een speciale simulatieomgeving te trainen om subtaakspecifieke vaardigheden te verwerven met behulp van het leerkader voor versterking (zie afbeelding 2 rechts). Dienovereenkomstig ontvangt een agent informatie over de toestand van de robot in zijn werkomgeving en selecteert op basis daarvan een actie om de robot in de ruimte te verplaatsen. Op deze manier kan elke robot zijn omgeving waarnemen en zich aanpassen aan veranderingen – een vermogen dat conventioneel geprogrammeerde manipulatoren slechts in zeer beperkte mate vertonen. Naast de status- en actieruimte moet een beloningsfunctie worden gedefinieerd die de acties van de agent evalueert in de vorm van een numeriek beloningssignaal. Het onderliggende algoritme gebruikt dit signaal om zijn interne beleid aan te passen – een mapping van toestanden naar acties – dat wordt weergegeven door een kunstmatig neuraal netwerk. Op basis van deze continue lus van waarnemen, doen en aanpassen, optimaliseert de agent geleidelijk zijn trajectplanning om de subtaak op de meest optimale manier te voltooien met betrekking tot goed gedefinieerde prestatie- en kwaliteitscriteria.
Nadat de vereiste agenten met succes zijn opgeleid, worden ze geïntegreerd in de voorwaardelijke controlestructuur die het multi-agentsysteem vertegenwoordigt. De resulterende modulaire architectuur van uitwisselbare en gespecialiseerde agents is bedoeld om de herbruikbaarheid van taakspecifieke leeromgevingen te bevorderen. De resulterende steeds groter wordende bibliotheek belooft de ontwikkelingsinspanningen voor toekomstige multi-robot use cases aanzienlijk te verminderen.
Beginnend op het niveau van de systeemarchitectuur, is een resultaat van het ontwikkelingsproces een client-serverarchitectuur die de communicatie mogelijk maakt tussen de Python-leeromgeving, waarin de managerlogica en het intelligente besturingsbeleid zijn geïmplementeerd, en de robotsimulatie (zie figuur 2 links ). De client-servercommunicatie is verantwoordelijk voor het verzenden van de stuurcommando’s naar de simulatie en voor het ontvangen van de bijbehorende simulatiereacties. Voor het gegeven geval van dubbele robot, omvat de besturingsstructuur twee agenten, één voor elke robot, die gelijktijdig de cilindrische pennen van de pallet op de draaitafel palletiseren. De leeromgevingen waarin de trajectplanners worden getraind, zijn op dezelfde manier gestructureerd: de observatie voor elke robot omvat de cartesiaanse positie van zijn TCP en een doelpositie die ofwel de pick- of de plaatspositie van de momenteel beschouwde pin vertegenwoordigt. De actievector die wordt voorspeld door het kunstmatige neurale netwerk is een zesdimensionaal cartesiaans positiecommando. De interne controller neemt dit commando over, voert inverse kinematica uit en stuurt de gewrichten van de manipulator dienovereenkomstig aan. Beide robots worden gelijktijdig in dezelfde simulatie getraind om samen te kunnen werken. De beloningsfunctie die evaluaties van de ondernomen acties terugkoppelt naar de agent, is ontworpen om afnemende afstanden tussen TCP en doelpositie te belonen, evenals afnemende trajectduur. Hierdoor worden de bijbehorende doelposities zeer tijdbesparend benaderd, maar zullen de robots ook met elkaar of met statische objecten in hun werkruimtes botsen. Om dit hoogst ongewenste gedrag te voorkomen, wordt een collisiedetectie verder geïmplementeerd en wordt het bijbehorende digitale collisiesignaal toegevoegd aan de beloningsfunctie. Door aanrijdingen te bestraffen, worden de agenten expliciet getraind om ongewenste contacten te voorkomen.
Resultaten
Afbeelding 3 toont het zich ontwikkelende beloningssignaal gedurende ongeveer twaalf uur training: in het begin is de beloning relatief laag en vertoont sterke pieken. Dit is een indicatie dat de agent de taak nog niet kan voltooien en dat er een groot aantal botsingen plaatsvindt. Naarmate de training vordert, neemt de beloning toe, vertoont minder pieken en convergeert naar de maximale totale beloning van nul. Dat er op latere tijdstippen toch pieken optreden, komt door het interne verkenningsgedrag van de agent, dat tijdens bedrijf wordt uitgeschakeld.
De laatste tests in de simulatie laten zien dat de twee robots botsingsvrije bewegingen uitvoeren in hun werkruimten en 86,14 seconden nodig hebben om de 16 pinnen te palletiseren. In vergelijking met een enkele, handmatig aangeleerde robot is dit een tijdswinst van 46%. Daarbij is aangetoond dat op simulatie gebaseerde autonome trajectplanning met behulp van versterkingsleren een veelbelovend alternatief blijkt te zijn voor conventioneel onderwijs, dat voor dergelijke complexere multi-robotsystemen uitgebreide handmatige inspanningen vereist, wat resulteert in langdurige opstart- en uitvalfasen. Bovendien blijkt de hiërarchische en modulaire aanpak bijzonder efficiënt te zijn bij het omgaan met verdere use-cases: door hergebruik van bestaande leeromgevingen, die mogelijk enigszins moeten worden aangepast aan nieuwe taken, nemen de ontwikkelingstijden geleidelijk af. Dienovereenkomstig worden de inspanningen voornamelijk beperkt tot het afleiden van de controlestructuur op een hoger niveau uit de structuur van de manipulatietaak, het bewaken van de trainingsprocessen en het valideren van de uiteindelijke multi-agentoplossing.
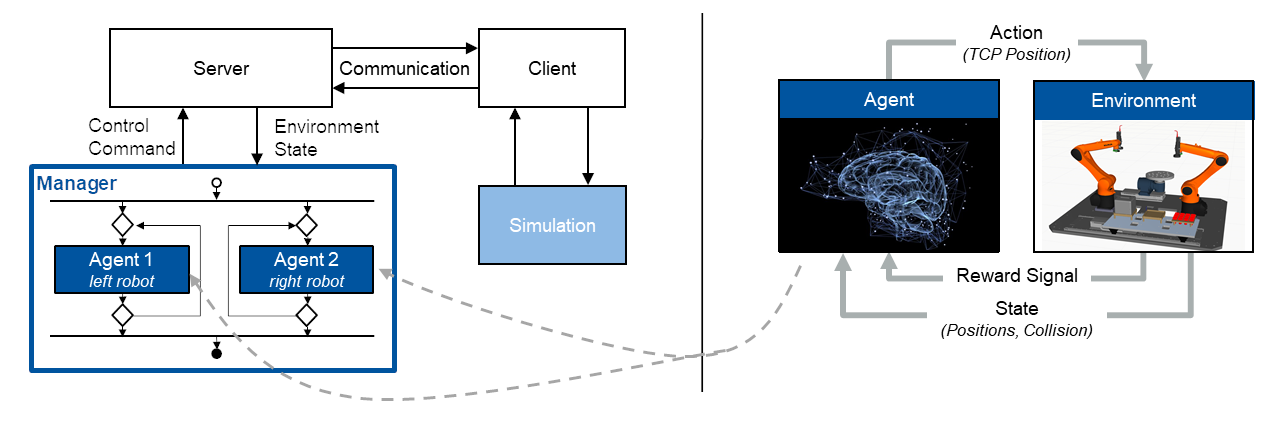
Afbeelding 2: Systeemarchitectuur en structuur manager-agent (links) en regelkring voor leren met diepgaande versterking (rechts)
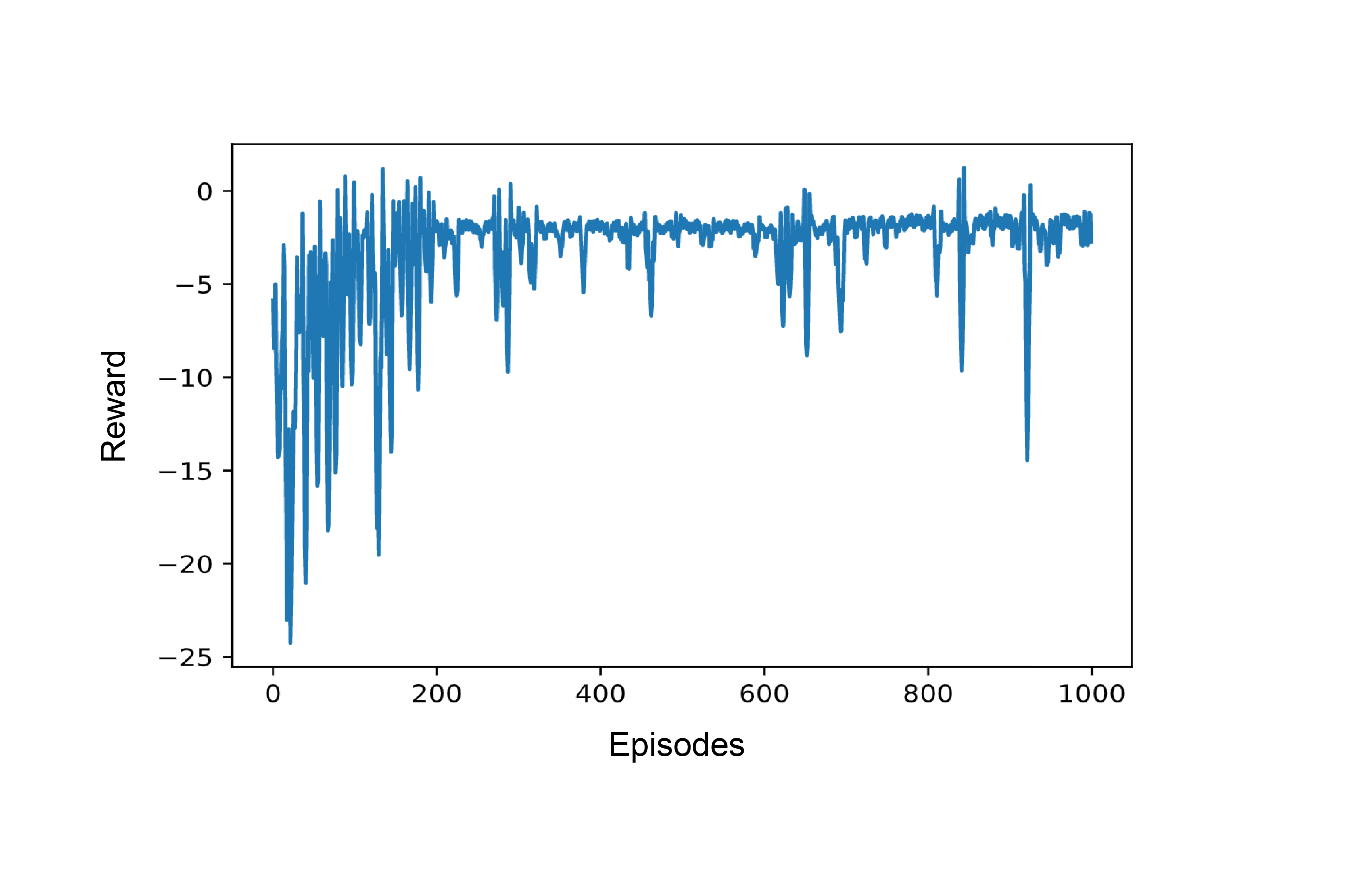
Figuur 3: Evolutie van het beloningssignaal dat door één agent per aflevering wordt ontvangen gedurende de gehele trainingsperiode van 1.000 afleveringen.
Conclusion
The presented approach shows that multiagent- systems based on deep reinforcement learning can enable efficient and full automated trajectory planning for dual-robot systems. Operation times can be decreased by 46 % in comparison to a single robot for the considered pick-and-place task. Future work will focus on a more complex dual mode manipulation task by handling a heavy component that exceeds the maximum payload of a single robot.
Lessons learned
• Simulations can be used for autonomous AI-based trajectory planning for dual robot systems
• While setting up the system architecture and especially the communication between simulation and learning environment, keep complexities
low at first and focus on a working infrastructure
• Once the infrastructure functions, perform short adapt-trainevaluate cycles on the learning environments to obtain the desired agent skills
• Even if trajectory planning is conducted autonomously, it will require an unneglectable amount of computational time