Together we are stronger – Data sharing for and by SMEs

Data plays an increasingly important role during production: from helping predict when your machine is due for maintenance, to assisting efficient planning and tracking of the production process. Although data is essential to all of these processes, such data must first be generated and then collected for use.
In the case of small and medium-sized businesses, it can be difficult to get hold of this data. Huge amounts of data are often needed before effective lessons can be learned from it, which can be difficult with limited production capacity or turnover. In addition, it is not enough to just generate a lot of data; the data must also be of good quality and preferably contain a wide range of machine behaviours.
Sometimes it is possible to supplement the existing data with synthetic data. By synthetic data, we mean all data that is artificially generated, as opposed to real data produced by real events. For example, a dataset of photos can be artificially expanded by flipping, rotating, zooming, and so on. Figure 1 shows a photo with six possible variations generated from the original. These new photos are clearly different from the original, but they are still photos of a kitten that can be used to train a model to recognize kittens. In this way, a dataset with photos can be enlarged dozens of times relatively easily.

Figure 1: Photo with possible variations
The best way to make more data available is to share it with each other. Four small and medium-sized companies, with five machines each, together create more data than one large company with 15 machines. However, sharing is easier said than done; for privacy reasons or to preserve company secrets, data is quite often not shared. In the rest of this blog, I will discuss two techniques that make it possible to share data, while maintaining privacy.
Synthetic data
The first technique is via synthetic data. In addition to datasets with photos, synthetic data can also be generated from numerical data. A new dataset can then be generated in which the actual values are adjusted while maintaining the same statistical properties and relationships. As a result, this new dataset contains the same relevant information from which to draw conclusions, while it will not contain any information about the actual production environment or company structure. Synthetic data can be used to filter sensitive data from (parts of) a dataset, like critical features of the products themselves, after which it can easily be shared with third parties. In this way, different datasets from different sources can be combined to capture and analyse a broader reach. A dataset can also be sent to an external party for analysis without worrying about privacy being violated.
Multi-Party Computation
The second method is Multi-Party Computation (MPC). MPC is a collective term for various techniques in which multiple parties can calculate something together without the personal input being made public. Figure 2 gives a simplified example in which Alice, Bob, and Charlie want to calculate their average hourly wage without learning each other’s hourly wage. Everyone starts by breaking down their hourly wage into three numbers (one for each). These parts are shared with each other so that everyone has one part of everyone else. Because everyone only gets one share, it is not possible to find out what the original hourly wage was. After this, everyone adds up their received parts and divides that by three (the number of participants). The sum of these three numbers is the average hourly wage of Alice, Bob, and Charlie. In this way, they can combine their data with each other and (in this case) calculate an average without learning anything about each other’s hourly wage. Obviously, more participants in this process will make it more effective.
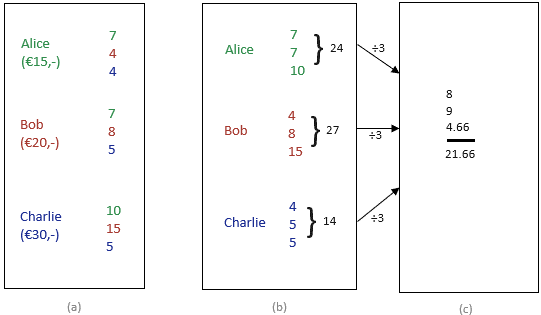
Figure 2: An example of MPC to calculate the average hourly wage. (a) Each hourly wage shall be divided into three and each shall receive 1 of these parts. (b) everyone adds up their parts and divides by 3. (c) the sum of these 3 numbers is the average hourly wage of Alice, Bob, and Charlie.
This MPC principle can be applied to many more applications. For example, it can be used by banks to jointly detect money laundering [1]. Through MPC, data can be combined between multiple companies to analyse more data for predictions without sharing sensitive data.
Conclusion
While it’s harder for small and medium-sized businesses to generate enough data to make accurate predictions, sharing data with each other to capture a wider reach can tip the balance. There are various techniques to share privacy-sensitive data with each other.
So, are you having problems with too little data? Whether it’s for machine maintenance, production planning, fault detection, or something else; join forces because together we are stronger.
Sources:
[1] https://appl-ai-tno.nl/projects/money-laundering-detection
