Samen staan we sterk – Data delen voor en door Mkb’s

Data speelt steeds een grotere rol tijdens de productie: van het voorspellen wanneer je machine aan onderhoud toe is tot het efficiënt inplannen en bijhouden van het productieproces. Voor alles is data nodig om er iets over te zeggen. Deze data moet alleen eerst gegenereerd worden.
Zeker voor midden- en kleinbedrijven kan het moeilijk zijn om aan deze data te komen. Er zijn enorme hoeveelheden data nodig voordat er lessen uit getrokken kunnen worden, wat lastig kan zijn bij beperkte productiecapaciteit of omzet. Daarnaast is het niet genoeg om alleen véél data te genereren; de data moet ook kwalitatief goed zijn en een breed bereik van machinegedrag bevatten.
Soms is het mogelijk om de bestaande data aan te vullen met synthetische data. Met synthetische data bedoelen we alle data die kunstmatig is gegenereerd, in tegenstelling tot echte data die wordt geproduceerd bij echte gebeurtenissen. Een dataset met foto’s kan bijvoorbeeld kunstmatig uitgebreid worden door foto’s te spiegelen, roteren, in te zoomen, enzovoort. Figuur 1 laat een foto zien met zes mogelijke variaties. Deze nieuwe foto’s zijn duidelijk anders dan het origineel, maar het blijven foto’s van een kat die gebruikt kunnen worden om een model te trainen om katten te herkennen. Op deze manier kan een dataset met foto’s relatief makkelijk tientallen keren vergroot worden.

Figuur 1: Foto met mogelijke variaties.
De beste manier om meer data beschikbaar te krijgen, blijft toch data delen met elkaar. Vier midden- en kleinbedrijven met elk vijf machines creëren samen meer data dan één groot bedrijf met vijftien machines. Nu is het delen van data makkelijker gezegd dan gedaan; om privacyredenen of om bedrijfsgeheimen te behouden wordt data vrij vaak niet gedeeld. In de rest van dit blog zal ik twee technieken bespreken die het mogelijk maken om toch data te delen, terwijl de privacy behouden wordt.
Synthetische data
De eerste techniek is via synthetische data. Naast datasets met foto’s, kan er ook synthetische data gegenereerd worden van numerieke data. Er wordt dan een nieuwe dataset gegenereerd waarin de daadwerkelijke waardes worden aangepast terwijl dezelfde statistische eigenschappen en relaties worden behouden. Deze nieuwe dataset bevat daardoor dezelfde relevante informatie om conclusies uit te halen terwijl het geen informatie bevat over de daadwerkelijke productieomgeving of bedrijfsstructuur. Synthetische data kan goed gebruikt worden om gevoelige data uit (delen van) een dataset te filteren waarna het makkelijk gedeeld kan worden met derde partijen. Op deze manier kunnen verschillende datasets van verschillende bronnen gecombineerd worden om een breder bereik vast te leggen en te analyseren. Ook kan een dataset naar een externe partij gestuurd worden voor analyse zonder zorgen dat de privacy geschonden wordt.
Multi-Party Computation
De tweede methode is Multi-Party Computation (MPC). MPC is een verzamelnaam voor verschillende technieken waarbij meerdere partijen samen iets kunnen uitrekenen zonder dat de persoonlijke input openbaar wordt gemaakt. Figuur 2 geeft een versimpeld voorbeeld waarin Alice, Bob en Charlie hun gemiddelde uurloon willen berekenen zonder dat ze elkaars uurloon leren. Iedereen begint met hun uurloon op te splitsen in drie getallen (voor ieder één). Deze delen worden met elkaar gedeeld zodat iedereen één deel van iedereen heeft. Omdat iedereen maar één deel krijgt, is het niet mogelijk om te achterhalen wat het originele uurloon was. Hierna telt iedereen hun ontvangen delen bij elkaar op en deelt dat door drie (het aantal deelnemers). De som van deze drie getallen is het gemiddelde uurloon van Alice, Bob en Charlie. Op deze manier kunnen ze dus hun data combineren met elkaar en (in dit geval) en gemiddelde uitrekenen zonder dat ze iets leren over het uurloon van elkaar.
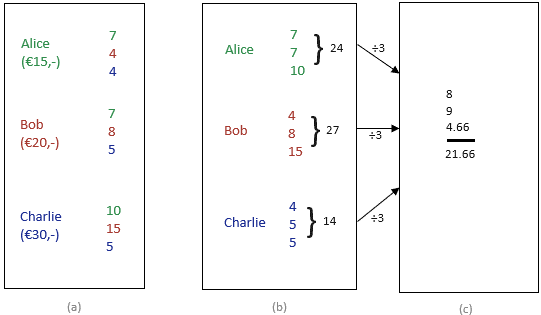
Figuur 2: Een voorbeeld van MPC om het gemiddelde uurloon te berekenen. (a) elk uurloon wordt in drieën gedeeld en iedereen krijgt 1 van deze delen. (b) iedereen telt hun delen bij elkaar op en delen dat door 3. (c) de som van deze 3 getallen is het gemiddelde uurloon van Alice, Bob en Charlie.
Dit MPC-principe kan op veel meer applicaties worden toegepast. Zo kan het bijvoorbeeld gebruikt worden door banken om samen witwassen op te sporen [1]. Via MPC kan dus data gecombineerd worden tussen meerdere bedrijven om meer data te analyseren voor voorspellingen zonder dat gevoelige data gedeeld wordt.
Conclusie
Dus, al is het moeilijker voor midden- kleinbedrijven om genoeg data te genereren om accurate voorspellingen te doen, data delen met elkaar om een breder bereik vast te leggen kan het evenwicht doen omslaan. Er zijn verschillende technieken om de privacygevoelige data toch te delen met elkaar. Dus heeft u problemen met te weinig data? Of het nou om machineonderhoud, productieplanning, foutdetectie, of iets anders gaat; sla de handen ineen want samen staan we sterk.
Bron:
[1] https://appl-ai-tno.nl/projects/money-laundering-detection
